Kinsta Affiliates
(Financial Web App)
Kinsta's home-rolled affiliate tracking system had found itself running for nearly 4 years without much maintenance or upgrading. But this left the system fragile, hard to maintain, and nearly impossible to effectively develop new features for. So a brownfield to greenfield rewrite was instituted to bring the project up to standards with the rest of the company's app suite.
Developer Experience First
Every aspect of the architecture, from the code, filestructure, and local environments to the pipeline deployments and repo management focuses on a good DX first and foremost. The application's excellent performance practically self-realizes as a result.
Monorepo
While not an org-wide monorepo, the app contains everything needed to run all of its services in one repo. This enables code sharing where valuable, while still maintaining a strict division of services within the structure, all orchestrated at the project root.

Yarn 2+ PnP
This was a game changer for everything from local work to deployment. When switching from PR to PR the ability to do so without having to run any dependency install made context switching nearly effortless. CI/CD didn't require any unique dependency management setup.
Playwright E2E
The most effective and broad testing coverage we could get was with end-to-end testing with Playwright. Being able to prevent regressions via the same user interactions that first detected them enabled rapid safety guard creation. All able to run locally and in pipelines, in a containerized, headless browser, all without the need to configure anything unique to the stack or individual libraries.
NoSQL Migration to SQL
A lot of the system's overall stability was gained just from the migration away from NoSQL. The migration alone detected and resolved several hidden, persistent issues such as duplicate accounts, disconnected relationships, and misattributed payments.
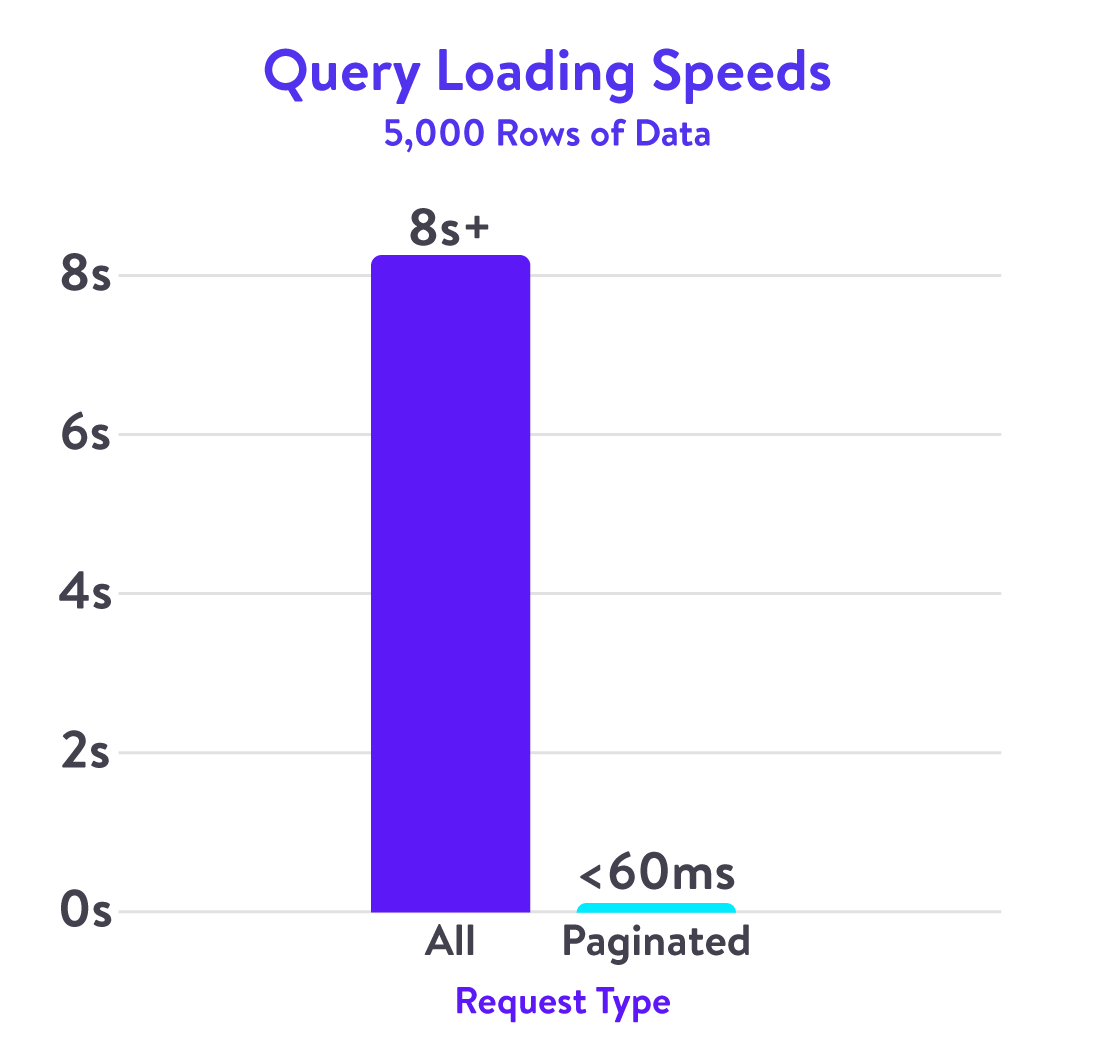
Performance Increase
Implementing a server-side GraphQL pagination technique that seamlessly integrated with our frontend table components resulted in a significant performance boost, with a 133X improvement in page load speed observed during load testing.
An Actual Graph
The previous GraphQL schema was 'view based'; Each page's request required a dedicated resolver tailored to its specific needs. This made it challenging to add new front-end structures as it required creating new backend resolvers for each case. The new schema and resolvers are designed to match the data's structural graph, allowing the data necessary for any view to be queried from all existing resolvers, increasing the flexibility and scalability of the system.
All resolvers work on the principle that with no arguments, you'd get 100% of the data set, and as you add arguments you filter down data to just selecting the nodes you need. Allowing complex front-end data queries and selection through UI without any backend modifications.
referrals(
filter: [{
where: {col: "idOwner", op: "=", expr: "ABC123"},
andWhere: {col: "isActive", op: "=", expr: true},
orWhere: {col: "created", op: "<", expr: $date}
}],
page: { limit: 10, offset: 3},
sort: { col: "created", dir: "ASC"}
)
# All
referrals {
nodes {
id
created
}
}
# All Paginated
referrals(page: { limit: 10, offset: 0}) {
nodes {
id
created
}
}
# Filtered
referrals(filter: [{
where: {col: "idOwner", op: "=", expr: "ABC123"}
}]) {
nodes {
id
created
}
}
Easy Auth
All data is resolved through a business logic layer/model of the entity that enforces authorization based on user ownership or role. Lifecycle hooks allow enforcement down to the field level based on which CRUD-type operation being performed.
This enables the devs to think just about performing the proper operation on the proper entity in the Mutation or Query resolver without worrying about data sensitivity.
Mutation: {
updateReferral: async(_, {args}, {identity}) => {
return Referral.query(identity).patch(args);
},
}